Posts tagged python
Automatically update pre-commit hook versions
- 03 December 2022
I figured out a way to automatically update all of the git pre-commit hook versions at once!
pre-commit is a useful command line tool for running simple commands before every git commit.
I use it to enforce things like flake8 and black in many of my projects.
subprocess.run can execute shell commands directly
- 29 November 2022
I often run shell commands in Python via the subprocess.run command.
One thing that has always bugged me is that this required you to split commands into a list before it’d work properly.
For example, you’d have to do:
Today I discovered that you don’t have to do this!
There’s a shell= keyword that can be used to tell subprocess to simply run the command directly in the shell.
I like Rust’s governance structure
- 18 October 2018
Recently I’ve been reading up on governance models for several large-ish open source projects. This is partially because I’m involved in a bunch of these projects myself, and partially because it’s fascinating to see distributed groups of people organizing themselves in effective (or not) ways on the internet.
Governance is tricky, because there is an inherent tension between:
Summer conference report back
- 01 August 2018
This is a short update on several of the conferences and workshops over the summer of this year. There’s all kinds of exciting things going on in open source and open communities, so this is a quick way for me to collect my thoughts on some things I’ve learned this summer.
Pangeo is a project that provides access to a gigantic geosciences dataset. They use lots of tools in the open-source community, including Dask for efficient numerical computation, the SciPy stack for a bunch of data analytics, and JupyterHub on Kubernetes for managing user instances and deploying on remote infrastructure. Pangeo has a neat demo of their hosted JupyterHub instance that people can use to access this otherwise-inaccessible dataset! See their video from SciPy below.
Adding copy buttons to code blocks in Sphinx
- 05 July 2018
NOTE: This is now a sphinx extension! Thanks to some friendly suggestions, I’ve written this up as a super tiny sphinx extension. Check it out here: https://github.com/choldgraf/sphinx-copybutton
Sphinx is a fantastic way to build documentation for your Python package. On the Jupyter project, we use it for almost all of our repositories.
Blogging with Jupyter Notebooks and Jekyll using nbconvert templates
- 23 May 2018
Here’s a quick (and hopefully helpful) post for those wishing to blog in
Jekyll using Jupyter notebooks. As some of you may know, nbconvert can
easily convert your .ipynb files to markdown, which Jekyll can easily
turn into blog posts for you.
However, an annoying part of this is that Markdown doesn’t include classes for input and outputs, which means they each get treated the same in the output. Not ideal.
An academic scientist goes to DevOps Days
- 18 May 2018
Last week I took a few days to attend DevOpsDays Silicon Valley. My goal was to learn a bit about how the DevOps culture works, what are the things people are excited about and discuss in this community. I’m also interested in learning a thing or two that could be brought back into the scientific / academic world. Here are a couple of thoughts from the experience.
tl;dr: DevOps is more about culture and team process than it is about technology, maybe science should be too…
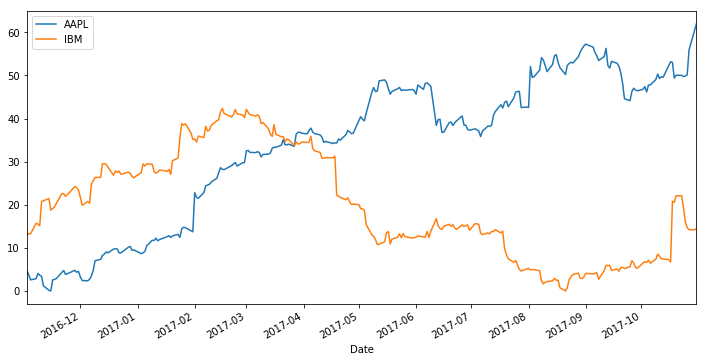
Combining dates with analysis visualization in python
- 02 November 2017
Sometimes you want to do two things:
Plot a timeseries that handles datetimes in a clever way (e.g., with Pandas or Matplotlib)
Dates in python
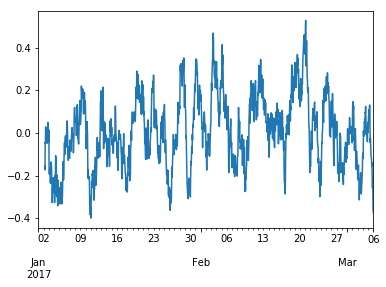
- 16 March 2017
As a part of setting up the website for the Docathon I’ve had to re-learn all of my date string formatting rules. It’s one of those little problems you don’t really think about - turning an arbitrary string into something structured like a date - until you’ve actually got to do it.
There are a bunch of tools in python for using date-like objects, but it’s not always easy to figure out how these work. This post is just a couple of pieces of information I’ve picked up along the process.
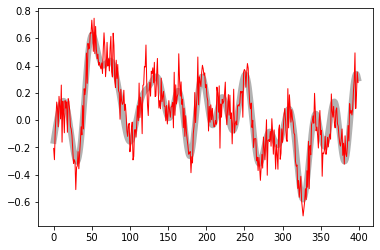
Matplotlib Cyclers are Great
- 04 January 2017
Every now and then I come across a nifty feature in Matplotlib that I wish I’d known about earlier. The MPL documentation can be a beast to get through, and as a result you miss some cool stuff sometimes.
This is a quick demo of one such feature: the cycler.
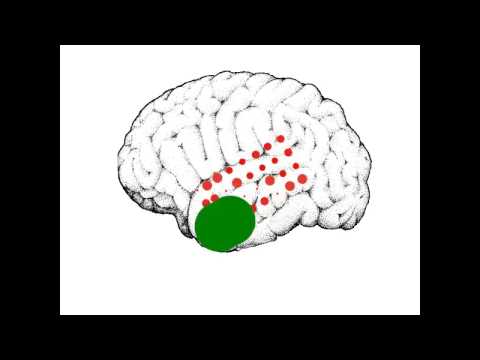
Brainy Jingle Bells
- 23 December 2016
This is a quick demo of how I created this video. Check it out below, or read on to see the code that made it!
Here’s a quick viz to show off some brainy holiday spirit.
The bleeding edge of publishing, Scraping publication amounts at biorxiv
- 19 December 2016
Per a recent request somebody posted on Twitter, I thought it’d be fun to write a quick scraper for the biorxiv, an excellent new tool for posting pre-prints of articles before they’re locked down with a publisher embargo.
A big benefit of open science is the ability to use modern technologies (like web scraping) to make new use of data that would originally be unavailable to the public. One simple example of this is information and metadata about published articles. While we’re not going to dive too deeply here, maybe this will serve as inspiration for somebody else interested in scraping the web.
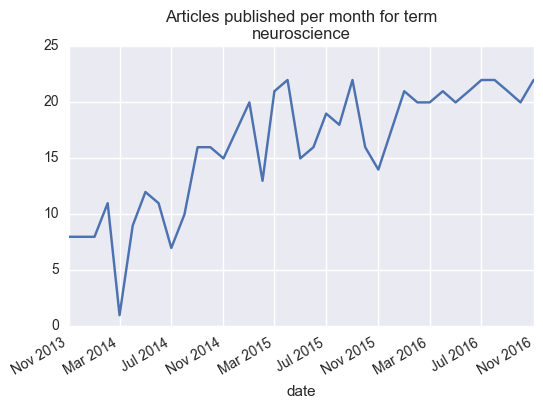
Visualizing publication bias
- 30 November 2016
This article is now interactive! Check out a live Binder instance here
In the next few months, I’ll try to take some time to talk about the things I learn as I make my way through this literature. While it’s easy to make one-off complaints to one another about how “science is broken” without really diving into the details, it’s important learn about how it’s broken, or at least how we could assess something like this.
5 things I learned at SciPy
- 01 November 2016
I’ve finally decompressed after my first go-around with Scipy. For those who haven’t heard of this conference before, Scipy is an annual meeting where members of scientific community get together to discuss their love of Python, scientific programming, and open science. It spans both academics and people from industry, making it a unique place in terms of how software interfaces with scientific research. (if you’re interested the full set of Scipy conferences, check out here.
It was an eye-opening experience that I learned a lot from, so here’s a quick recap of some things that I learned during my first rodeo.
Could Brexit have happened by chance?
- 08 July 2016
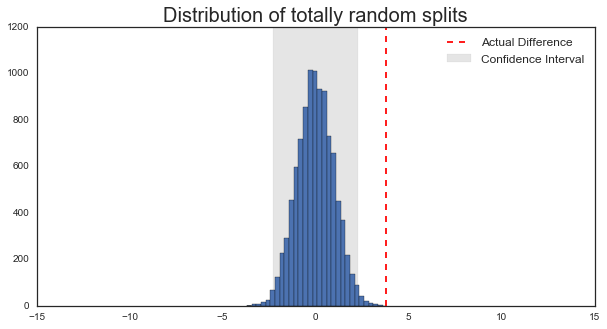
As a scientist, watching the Brexit vote was a little bit painful. Though probably not for the reason you’re thinking. No, it wasn’t the politics that bothered me, but the method for making such an incredibly important decision. Let me explain…
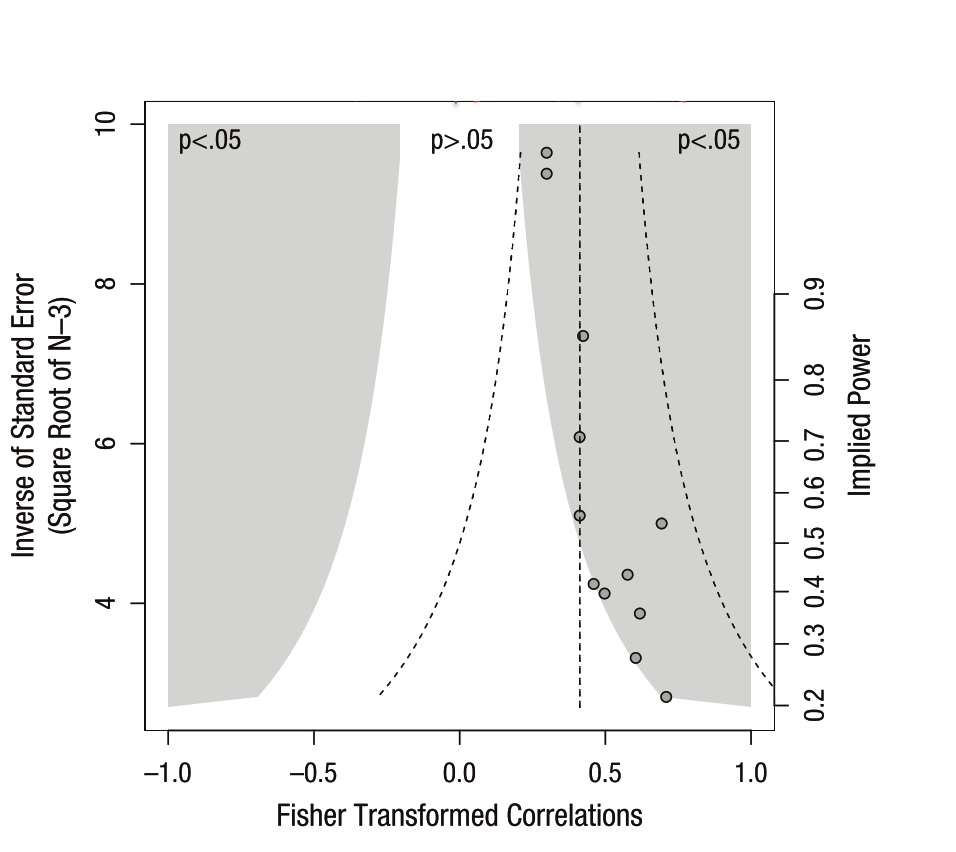
Scientists are a bit obsessed with the concept of error. In the context of collecting data and anaylzing it, this takes the form of our “confidence” in the results. If all the data say the same thing, then we are usually pretty confident in the overall message. If the data is more complicated than this (and it always is), then we need to define how confident we are in our conclusions.
The beauty of computational efficiency
- 02 July 2016
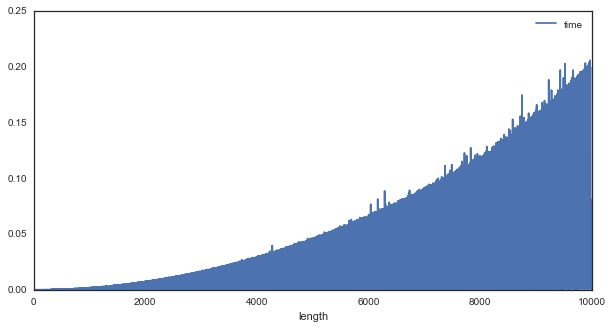
When we discuss “computational efficiency”, you often hear people throw around phrases like $O(n^2)$ or $O(nlogn)$. We talk about them in the abstract, and it can be hard to appreciate what these distinctions mean and how important they are. So let’s take a quick look at what computational efficiency looks like in the context of a very famous algorithm: The Fourier Transform.
Briefly, A Fourier Transform is used for uncovering the spectral information that is present in a signal. AKA, it tells us about oscillatory components in the signal, and has a wide range of uses in communications, signal processing, and even neuroscience analysis.
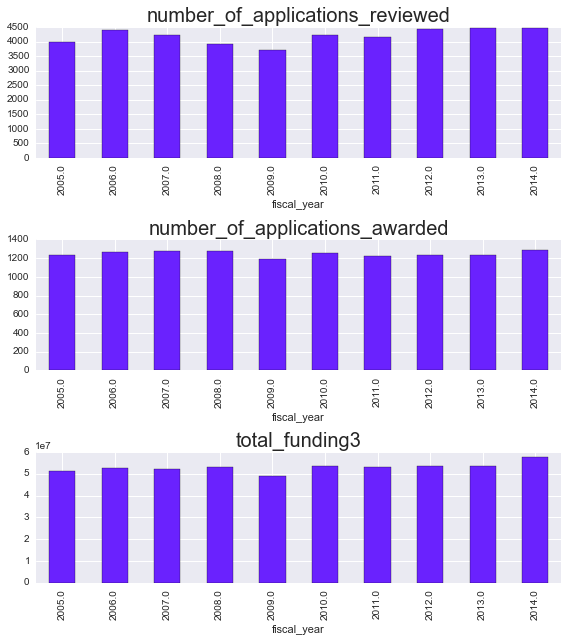
NIH grant analysis
- 29 October 2015
As I’m entering the final years of graduate school, I’ve been applying for a few typical “pre-doc” fellowships. One of these is the NRSA, which is notorious for requiring you to wade through forests of beaurocratic documents (seriously, their “guidelines” for writing an NRSA are over 100 pages!). Doing so ends up taking a LOT of time.
This got me wondering what kind of success rates these grants have in the first place. For those who haven’t gone through the process before, it’s a bit opaque:
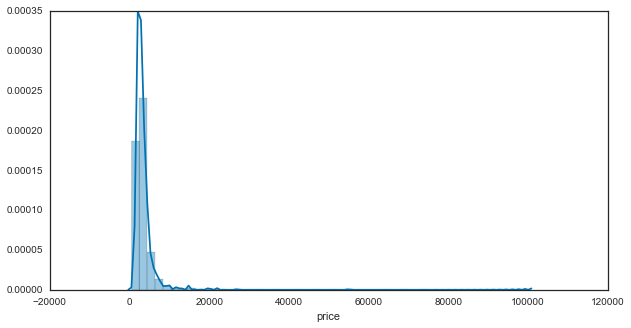
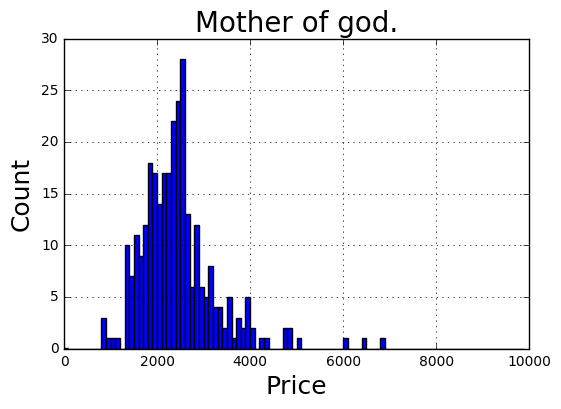
Craigslist data analysis
- 27 September 2015
In the last post I showed how to use a simple python bot to scrape data from Criagslist. This is a quick follow-up to take a peek at the data.
Note - data that you scrape from Craigslist is pretty limited. They tend to clear out old posts, and you can only scrape from recent posts anyway to avoid them blocking you.
Scraping craigslist
- 30 August 2015
In this notebook, I’ll show you how to make a simple query on Craigslist using some nifty python modules. You can take advantage of all the structure data that exists on webpages to collect interesting datasets.
First we need to figure out how to submit a query to Craigslist. As with many websites, one way you can do this is simply by constructing the proper URL and sending it to Craigslist. Here’s a sample URL that is returned after manually typing in a search to Craigslist:
Coherence correlation
- 27 May 2015
Note - you can find the nbviewer of this post here
A big question that I’ve always wrestled with is the difference between correlation and coherence. Intuitively, I think of these two things as very similar to one another. Correlation is a way to determine the extent to which two variables covary (normalized to be between -1 and 1). Coherence is similar, but instead assesses “similarity” by looking at the similarity for two variables in frequency space, rather than time space.
