Posts tagged web scraping
The bleeding edge of publishing, Scraping publication amounts at biorxiv
- 19 December 2016
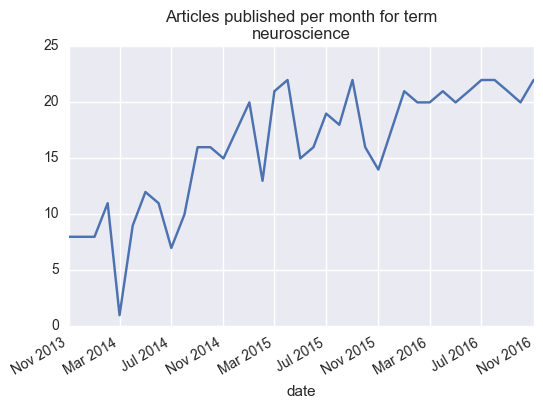
Per a recent request somebody posted on Twitter, I thought it’d be fun to write a quick scraper for the biorxiv, an excellent new tool for posting pre-prints of articles before they’re locked down with a publisher embargo.
A big benefit of open science is the ability to use modern technologies (like web scraping) to make new use of data that would originally be unavailable to the public. One simple example of this is information and metadata about published articles. While we’re not going to dive too deeply here, maybe this will serve as inspiration for somebody else interested in scraping the web.