Posts in til
A few random opportunities in AI for Social Good
- 02 October 2023
Recently a few friends have reached out asking if I knew of any opportunities to work on AI-related things that also have some kind of pro-social tie-in. I think a lof people see AI as a technology with a lot of potential, but in an environment of companies that don’t seem to prioritize the benefit of human-kind over the never-ending hype machine and the promise of hyperscale growth.
So I asked around a few places to see if folks had recommendations for using skills in machine learning or artificial intelligence, but in a context that was explicitly for the benefit of humanity or otherwise pro-social. Here are a few that stood out (they are 100% not vetted, I’m just passing along information in case it’s useful so please tell me if there’s something wrong or problematic in here):
A Sphinx directive for social media embeds
- 15 February 2023
I often want to link to social and other types of web-based media in my Sphinx documentation and blog. Rather than embedding it all in custom HTML code, I decided to write a little wrapper to turn it into a directive.
It’s called {socialpost}, and it works with Twitter, Mastodon, and YouTube links.
Bundle extensions with your Sphinx theme
- 19 January 2023
Sphinx is great because it has a ton of useful extensions that let you grow its functionality. However, a downside of this is that users have to actually learn about those extensions and activate them manually. It’s not hard, but it’s a non-trivial amount of discovery work.
One way to solve this is for themes to bundle extensions on their own. This way they can include functionality via an extension rather than writing custom code on their own.
Install dependencies from GitHub with pyproject.toml or requirements.txt
- 31 December 2022
This is a short post to demonstrate how to install packages directly from GitHub with pyprojects.toml or requirements.txt, including custom branches and commits.
It will focus on pyprojects.toml because this is newer and there’s less information about it, but the general pattern holds for requirements.txt as well.
In pyproject.toml, you can specify dependencies for a project via the dependencies field.
For example, to specify Sphinx as a dependency:
Load and plot a remote font with Matplotlib
- 06 December 2022
As part of my sphinx-social-previews prototype, I wanted to be able to use the Roboto Font from Google in image previews.
However, Roboto is often not loaded on your local filesystem, so it took some digging to figure out how to make it possible to load via Matplotlib’s text plotting functionality.
Here’s the solution that finally worked for me, inspired from this Tweet with a similar implementation from the dmol book.

How to update Sphinx options during the build
- 05 December 2022
As part of the pydata-sphinx-theme we have a few settings that auto-enable extensions and configure them on behalf of the user.
It has always been mysterious to me how to do this properly during the Sphinx build.
It’s easy to configure things with conf.py ahead of time, but what if you want to manually set a value during the build?
I finally figured it out, so documenting the process here.
Automatically update pre-commit hook versions
- 03 December 2022
I figured out a way to automatically update all of the git pre-commit hook versions at once!
pre-commit is a useful command line tool for running simple commands before every git commit.
I use it to enforce things like flake8 and black in many of my projects.
subprocess.run can execute shell commands directly
- 29 November 2022
I often run shell commands in Python via the subprocess.run command.
One thing that has always bugged me is that this required you to split commands into a list before it’d work properly.
For example, you’d have to do:
Today I discovered that you don’t have to do this!
There’s a shell= keyword that can be used to tell subprocess to simply run the command directly in the shell.
Fix phantom GitHub workflows in your ci-cd with protected branch rules
- 27 November 2022
Have you ever had a GitHub pull request show “phantom” workflows that never pass? This looks like one or more workflows that are in a constant waiting state, with a yellow status indicator, and that never complete.
It looks something like this:

Custom roles and domains in Sphinx with one line
- 21 November 2022
I was working on the roles and structure section of the 2i2c Team Compass and found a nifty feature in Sphinx that I hadn’t known before.
You can currently add labels to any section with the following MyST Markdown structure:
Automatically updating my publications page with ORCID and doi.org
- 19 November 2022
For a while I’ve had a hand-crafted .bibtex file stored locally for my publications/ page.
However, manually updating local text file is a pain to remember, especially since there are many services out there that automatically track new publications.
A helpful suggestion on Twitter allowed me to include the full citation information, including lists of authors, using the doi.org API!
Automatically redirect folders in Sphinx websites
- 19 November 2022
I spent a bit of time today updating my website after some changes in the MyST-NB and Sphinx Design ecosystems.
Along the way, I decided to redirect /posts/ to /blog/, since it seems /blog/ is a much more common folder to use for blog posts.
This posed a problem, because the sphinx-rediraffe extension does not allow you to redirect folders with wildcards.
AKA, you cannot do:
Serving in two roles at once via pre-recorded tutorials
- 17 December 2021
At AGU 2021 this year I was asked to give a short tutorial introduction to Jupyter Book. The tutorial was 30 minutes long, and the session was fully remote.
This posed a few challenges:

Build a simple timeline with sphinx-design
- 22 January 2020
One of the nice things about MyST Markdown is that it is extensible. Any Sphinx extension will work with MyST Markdown (in the context of Jupyter Book, anyway).
One of my favorite Sphinx extensions is Sphinx Design, this brings you flexible UI components that use Bootstrap CSS under the hood (though without heavy javascript). They let you do things like this:
Testing Pandoc and Jupyter Notebooks
- 11 November 2019
For several months now, the universal document converter pandoc has
had support for Jupyter Notebooks. This means that with a single call,
you can convert .ipynb files to any of the output formats that Pandoc
supports (and vice-versa!). This post is a quick exploration of what this
looks like.
Note that for this post, we’re using Pandoc version 2.7.3. Also, some of what’s below is hard to interpret without actually opening the files that are created by Pandoc. For the sake of this blog post, I’m going to stick with the raw text output here, though you can expand the outputs if you wish, I recommend copy/pasting some of these commands on your own if you’d like to try.
Automatically mirror a github repository with CircleCI
- 18 December 2018
tl;dr: you can automatically mirror the contents of one repository to another by using CI/CD services like CircleCI. This post shows you one way to do it using secrets that let you push to a GitHub repository from a CircleCI process.
We recently ran into an issue with the Data 8 course where we needed to mirror one GitHub site to another. In short, the textbook is built with a tool called jupyter-book, and we use github-pages to host the content at inferentialthinking.com. For weird URL-naming reasons, we had to create a second organization to host the actual site. This introduced the complexity that any time the textbook had to be updated, we did so in two different places. The raw textbook content is hosted at https://github.com/data-8/textbook, and the version hosted online is at https://github.com/inferentialthinking/inferentialthinking.github.io.
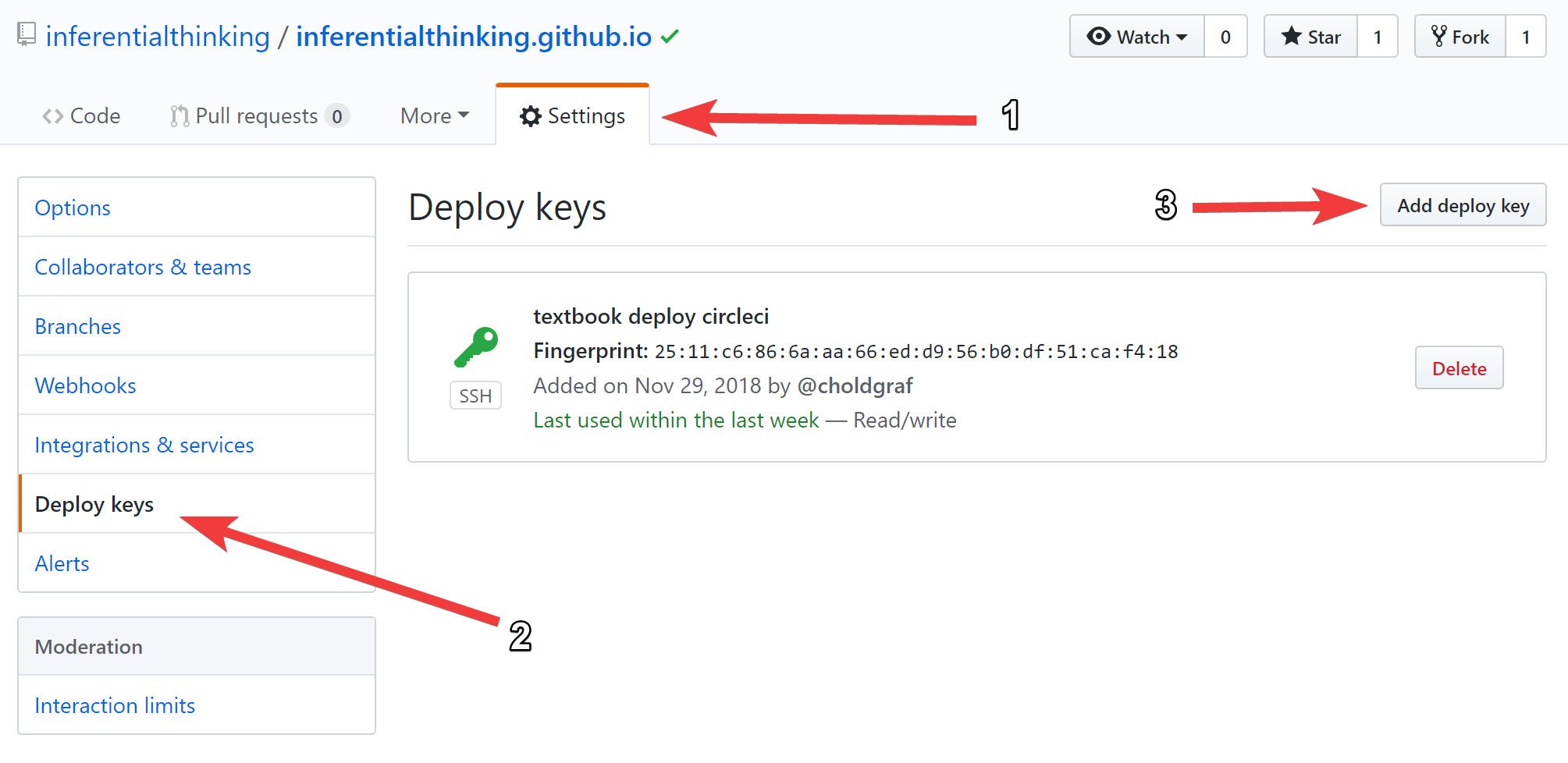
My weekly workflow
- 26 October 2018
I’ve had a bunch of conversations with friends who were interested in how to keep track of the various projects they’re working on, and to prioritize their time over the course of a week. I thought it might be helpful to post my own approach to planning time throughout the week in case it’s useful for others to riff off of.
First off, a few general principles that I use to guide my thinking on planning out the week.
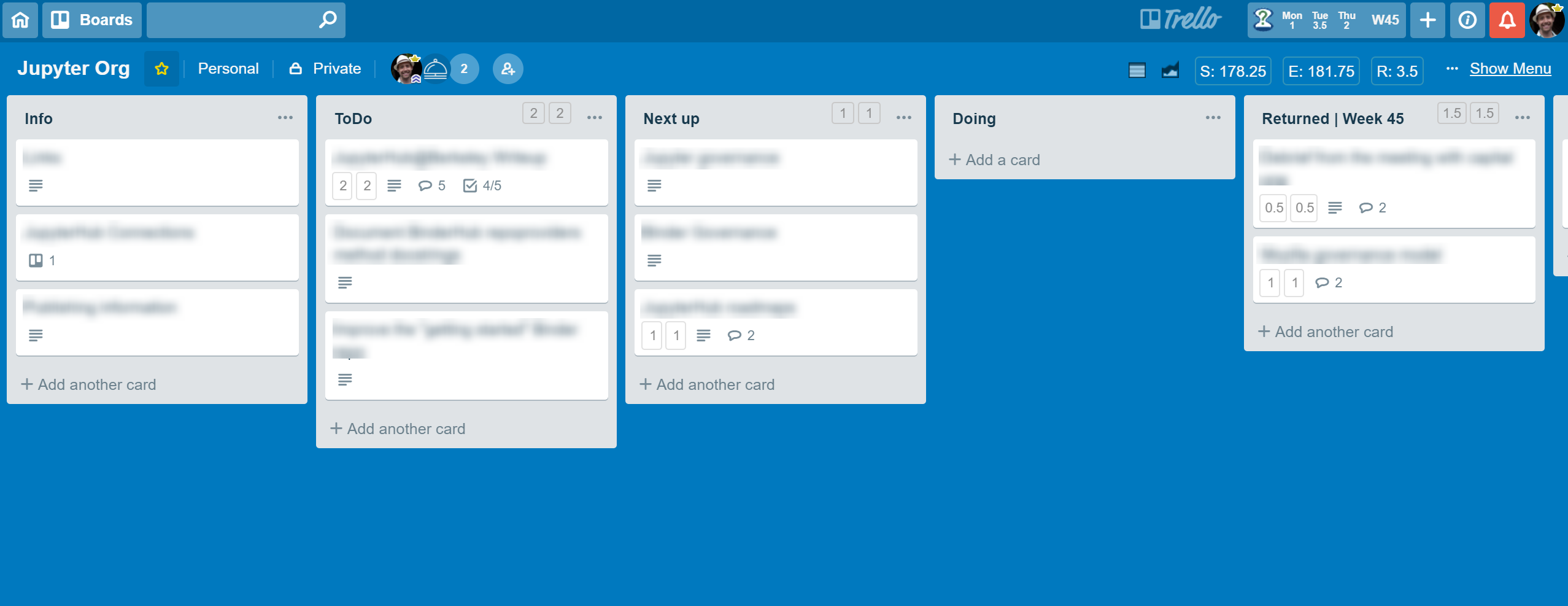
Using CircleCI to preview documentation in Pull Requests
- 16 October 2018
Writing documentation is important - it’s the first point of contact between many users and your project, and can be a pivotal moment in whether they decide to adopt your tech or become a contributor.
However, it can be a pain to iterate on documentation, as it is often involves a lot of rapid iteration locally, followed by a push to GitHub where you “just trust” that the author has done a good job of writing content, design, etc.

Adding copy buttons to code blocks in Sphinx
- 05 July 2018
NOTE: This is now a sphinx extension! Thanks to some friendly suggestions, I’ve written this up as a super tiny sphinx extension. Check it out here: https://github.com/choldgraf/sphinx-copybutton
Sphinx is a fantastic way to build documentation for your Python package. On the Jupyter project, we use it for almost all of our repositories.
Introducing _makeitpop_, a tool to perceptually warp your data!
- 04 June 2018
It should go without saying, but you should never do the stuff that you’re about to read about here. Data is meant to speak for itself, and our visualizations should accurately reflect the data above all else.*
When I was in graduate school, I tended to get on my soapbox and tell everybody why they should stop using Jet and adopt a “perceptually-flat” colormap like viridis, magma, or inferno.
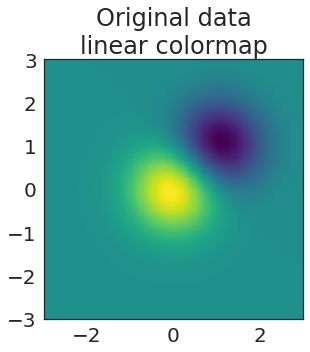
Blogging with Jupyter Notebooks and Jekyll using nbconvert templates
- 23 May 2018
Here’s a quick (and hopefully helpful) post for those wishing to blog in
Jekyll using Jupyter notebooks. As some of you may know, nbconvert can
easily convert your .ipynb files to markdown, which Jekyll can easily
turn into blog posts for you.
However, an annoying part of this is that Markdown doesn’t include classes for input and outputs, which means they each get treated the same in the output. Not ideal.
Combining dates with analysis visualization in python
- 02 November 2017
Sometimes you want to do two things:
Plot a timeseries that handles datetimes in a clever way (e.g., with Pandas or Matplotlib)
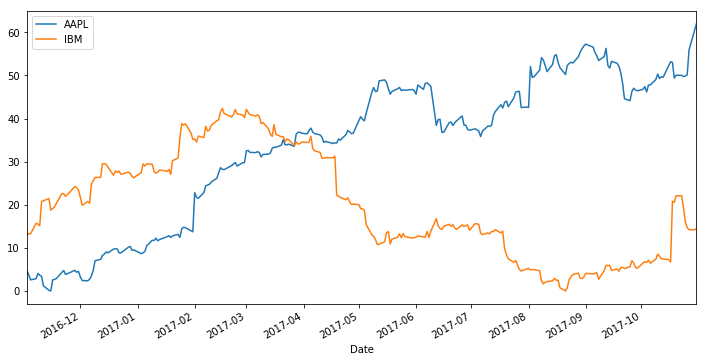
Dates in python
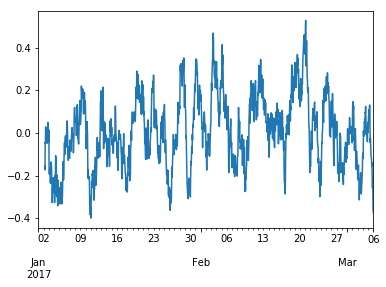
- 16 March 2017
As a part of setting up the website for the Docathon I’ve had to re-learn all of my date string formatting rules. It’s one of those little problems you don’t really think about - turning an arbitrary string into something structured like a date - until you’ve actually got to do it.
There are a bunch of tools in python for using date-like objects, but it’s not always easy to figure out how these work. This post is just a couple of pieces of information I’ve picked up along the process.
Matplotlib Cyclers are Great
- 04 January 2017
Every now and then I come across a nifty feature in Matplotlib that I wish I’d known about earlier. The MPL documentation can be a beast to get through, and as a result you miss some cool stuff sometimes.
This is a quick demo of one such feature: the cycler.
Brainy Jingle Bells
- 23 December 2016
This is a quick demo of how I created this video. Check it out below, or read on to see the code that made it!
Here’s a quick viz to show off some brainy holiday spirit.
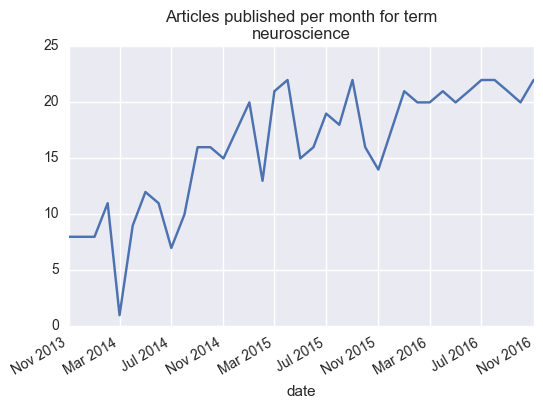
The bleeding edge of publishing, Scraping publication amounts at biorxiv
- 19 December 2016
Per a recent request somebody posted on Twitter, I thought it’d be fun to write a quick scraper for the biorxiv, an excellent new tool for posting pre-prints of articles before they’re locked down with a publisher embargo.
A big benefit of open science is the ability to use modern technologies (like web scraping) to make new use of data that would originally be unavailable to the public. One simple example of this is information and metadata about published articles. While we’re not going to dive too deeply here, maybe this will serve as inspiration for somebody else interested in scraping the web.
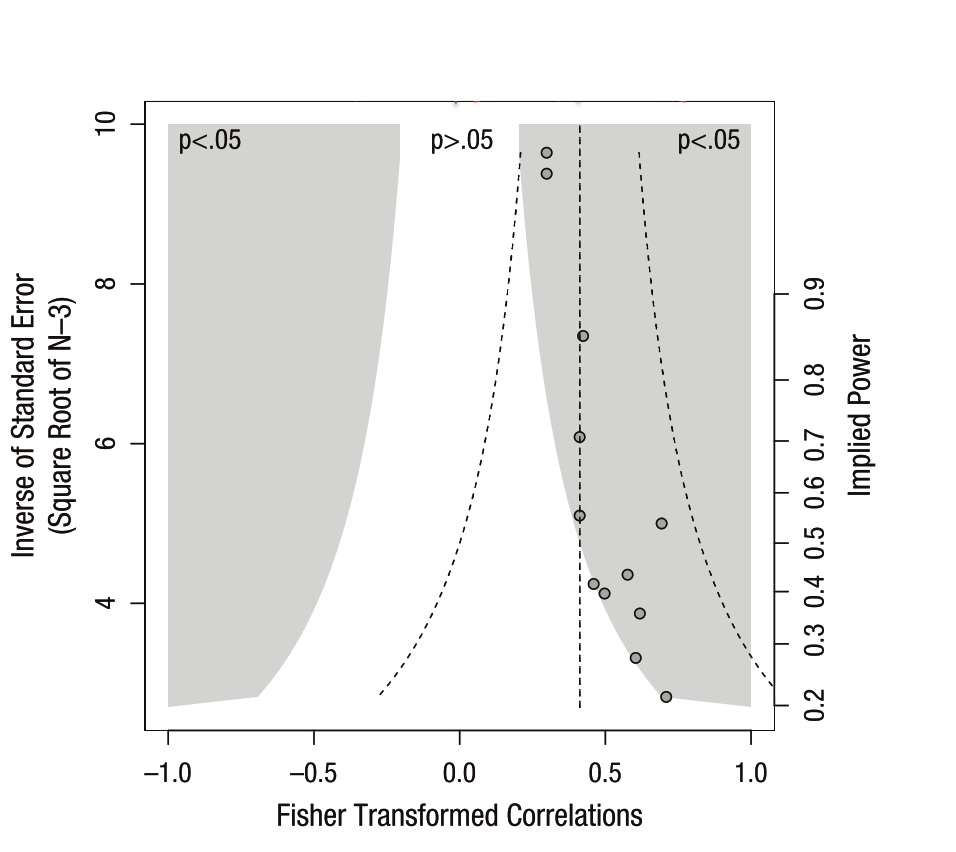
Visualizing publication bias
- 30 November 2016
This article is now interactive! Check out a live Binder instance here
In the next few months, I’ll try to take some time to talk about the things I learn as I make my way through this literature. While it’s easy to make one-off complaints to one another about how “science is broken” without really diving into the details, it’s important learn about how it’s broken, or at least how we could assess something like this.
5 things I learned at SciPy
- 01 November 2016
I’ve finally decompressed after my first go-around with Scipy. For those who haven’t heard of this conference before, Scipy is an annual meeting where members of scientific community get together to discuss their love of Python, scientific programming, and open science. It spans both academics and people from industry, making it a unique place in terms of how software interfaces with scientific research. (if you’re interested the full set of Scipy conferences, check out here.
It was an eye-opening experience that I learned a lot from, so here’s a quick recap of some things that I learned during my first rodeo.
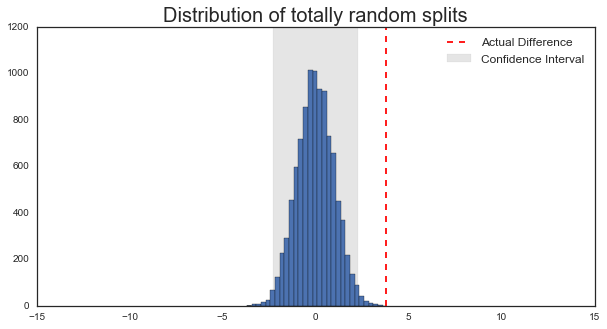
Could Brexit have happened by chance?
- 08 July 2016
As a scientist, watching the Brexit vote was a little bit painful. Though probably not for the reason you’re thinking. No, it wasn’t the politics that bothered me, but the method for making such an incredibly important decision. Let me explain…
Scientists are a bit obsessed with the concept of error. In the context of collecting data and anaylzing it, this takes the form of our “confidence” in the results. If all the data say the same thing, then we are usually pretty confident in the overall message. If the data is more complicated than this (and it always is), then we need to define how confident we are in our conclusions.
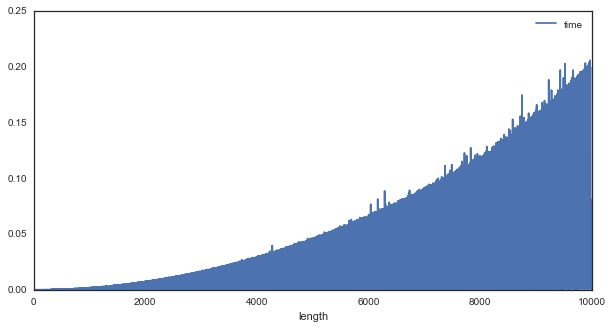
The beauty of computational efficiency
- 02 July 2016
When we discuss “computational efficiency”, you often hear people throw around phrases like $O(n^2)$ or $O(nlogn)$. We talk about them in the abstract, and it can be hard to appreciate what these distinctions mean and how important they are. So let’s take a quick look at what computational efficiency looks like in the context of a very famous algorithm: The Fourier Transform.
Briefly, A Fourier Transform is used for uncovering the spectral information that is present in a signal. AKA, it tells us about oscillatory components in the signal, and has a wide range of uses in communications, signal processing, and even neuroscience analysis.
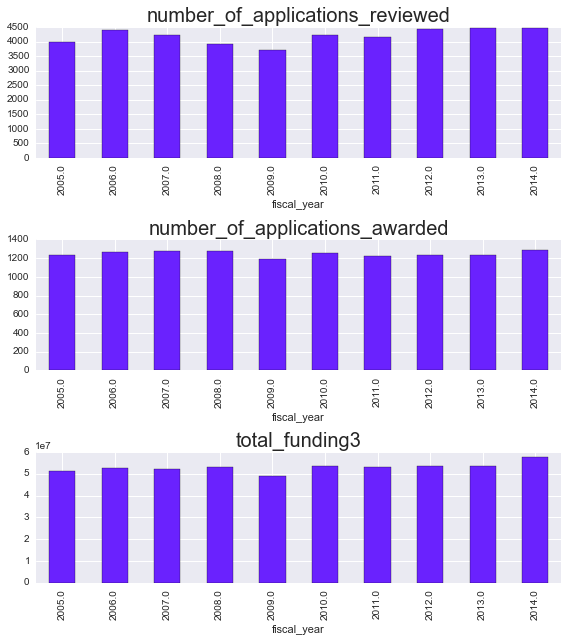
NIH grant analysis
- 29 October 2015
As I’m entering the final years of graduate school, I’ve been applying for a few typical “pre-doc” fellowships. One of these is the NRSA, which is notorious for requiring you to wade through forests of beaurocratic documents (seriously, their “guidelines” for writing an NRSA are over 100 pages!). Doing so ends up taking a LOT of time.
This got me wondering what kind of success rates these grants have in the first place. For those who haven’t gone through the process before, it’s a bit opaque:
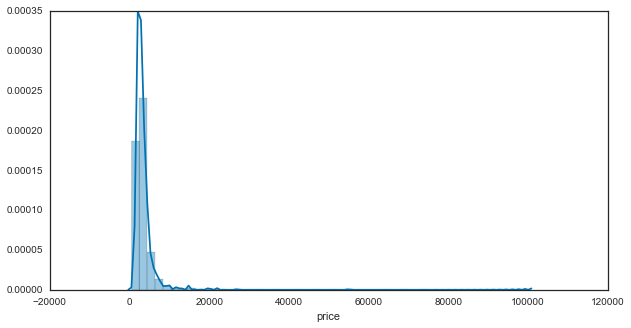
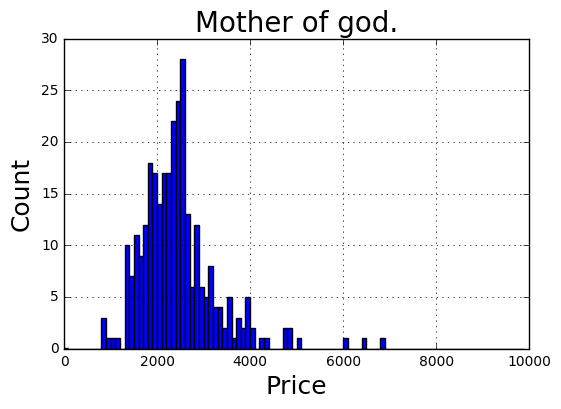
Craigslist data analysis
- 27 September 2015
In the last post I showed how to use a simple python bot to scrape data from Criagslist. This is a quick follow-up to take a peek at the data.
Note - data that you scrape from Craigslist is pretty limited. They tend to clear out old posts, and you can only scrape from recent posts anyway to avoid them blocking you.
Scraping craigslist
- 30 August 2015
In this notebook, I’ll show you how to make a simple query on Craigslist using some nifty python modules. You can take advantage of all the structure data that exists on webpages to collect interesting datasets.
First we need to figure out how to submit a query to Craigslist. As with many websites, one way you can do this is simply by constructing the proper URL and sending it to Craigslist. Here’s a sample URL that is returned after manually typing in a search to Craigslist:
Coherence correlation
- 27 May 2015
Note - you can find the nbviewer of this post here
A big question that I’ve always wrestled with is the difference between correlation and coherence. Intuitively, I think of these two things as very similar to one another. Correlation is a way to determine the extent to which two variables covary (normalized to be between -1 and 1). Coherence is similar, but instead assesses “similarity” by looking at the similarity for two variables in frequency space, rather than time space.
