Posted in 2016
Brainy Jingle Bells
- 23 December 2016
This is a quick demo of how I created this video. Check it out below, or read on to see the code that made it!
Here’s a quick viz to show off some brainy holiday spirit.
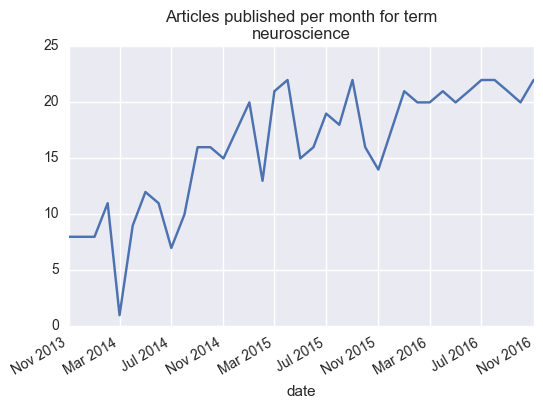
The bleeding edge of publishing, Scraping publication amounts at biorxiv
- 19 December 2016
Per a recent request somebody posted on Twitter, I thought it’d be fun to write a quick scraper for the biorxiv, an excellent new tool for posting pre-prints of articles before they’re locked down with a publisher embargo.
A big benefit of open science is the ability to use modern technologies (like web scraping) to make new use of data that would originally be unavailable to the public. One simple example of this is information and metadata about published articles. While we’re not going to dive too deeply here, maybe this will serve as inspiration for somebody else interested in scraping the web.
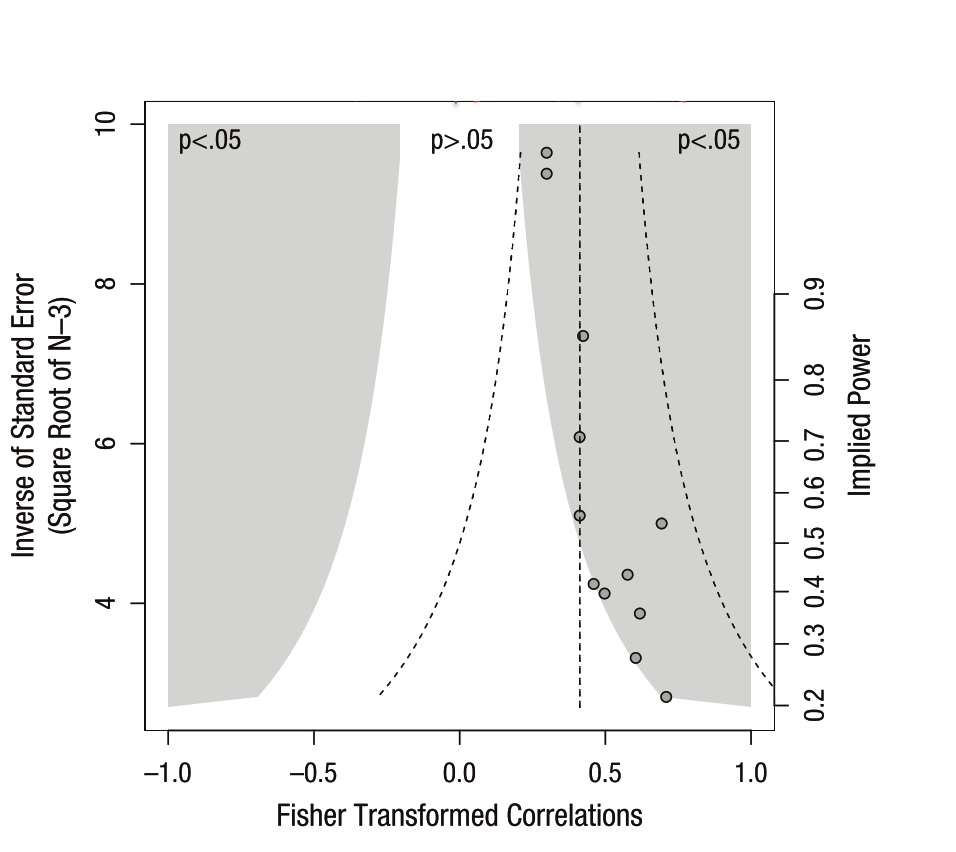
Visualizing publication bias
- 30 November 2016
This article is now interactive! Check out a live Binder instance here
In the next few months, I’ll try to take some time to talk about the things I learn as I make my way through this literature. While it’s easy to make one-off complaints to one another about how “science is broken” without really diving into the details, it’s important learn about how it’s broken, or at least how we could assess something like this.
5 things I learned at SciPy
- 01 November 2016
I’ve finally decompressed after my first go-around with Scipy. For those who haven’t heard of this conference before, Scipy is an annual meeting where members of scientific community get together to discuss their love of Python, scientific programming, and open science. It spans both academics and people from industry, making it a unique place in terms of how software interfaces with scientific research. (if you’re interested the full set of Scipy conferences, check out here.
It was an eye-opening experience that I learned a lot from, so here’s a quick recap of some things that I learned during my first rodeo.
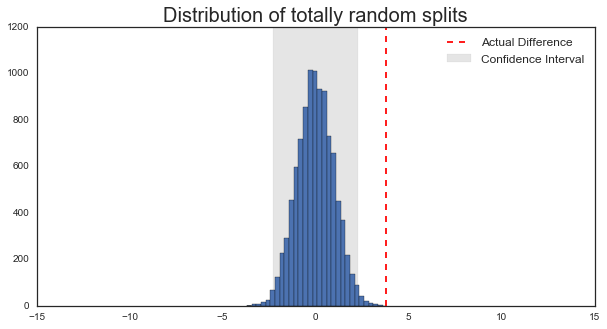
Could Brexit have happened by chance?
- 08 July 2016
As a scientist, watching the Brexit vote was a little bit painful. Though probably not for the reason you’re thinking. No, it wasn’t the politics that bothered me, but the method for making such an incredibly important decision. Let me explain…
Scientists are a bit obsessed with the concept of error. In the context of collecting data and anaylzing it, this takes the form of our “confidence” in the results. If all the data say the same thing, then we are usually pretty confident in the overall message. If the data is more complicated than this (and it always is), then we need to define how confident we are in our conclusions.
The beauty of computational efficiency
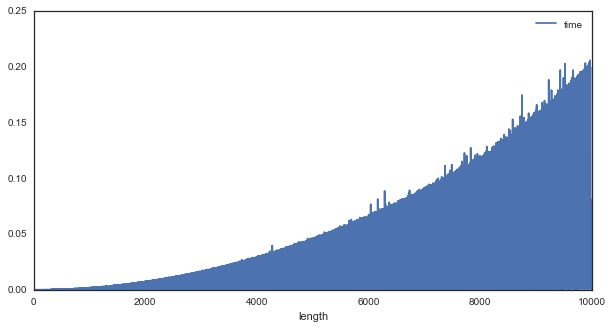
- 02 July 2016
When we discuss “computational efficiency”, you often hear people throw around phrases like $O(n^2)$ or $O(nlogn)$. We talk about them in the abstract, and it can be hard to appreciate what these distinctions mean and how important they are. So let’s take a quick look at what computational efficiency looks like in the context of a very famous algorithm: The Fourier Transform.
Briefly, A Fourier Transform is used for uncovering the spectral information that is present in a signal. AKA, it tells us about oscillatory components in the signal, and has a wide range of uses in communications, signal processing, and even neuroscience analysis.